ScrapBookはFirefoxのプラグインで、ホームページをリンク階層を含めてごそっと保存できるものです。
旧はぅ君プロジェクトを閉鎖する際、ページだけは残しておきたかったので、このプラグインで全ページをダウンロードしました。
リンク先URLなどは、問題ないように全てきれいに書き変わりますが、そのページ名は独自のものに変ってしまう点が注意点です。
使い方手順
1.プラグイン導入
ScrapBookのプラグインページに行き、「Add to Firefox」でインストールします。
2.保存設定
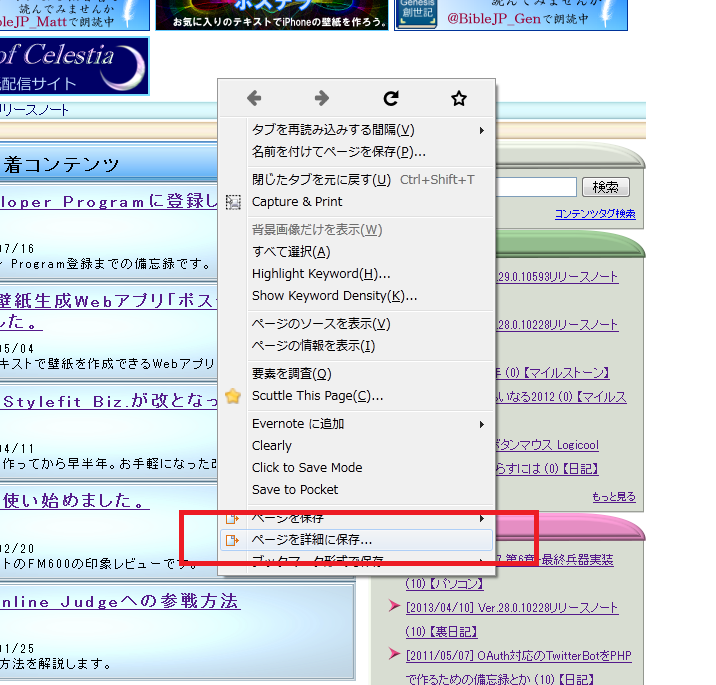
プラグインを導入すると、右クリックメニューが拡張されて「ページを詳細に保存」が現れますので、クリックします。
3.保存の詳細
設定ダイアログが開くので、設定していきます。
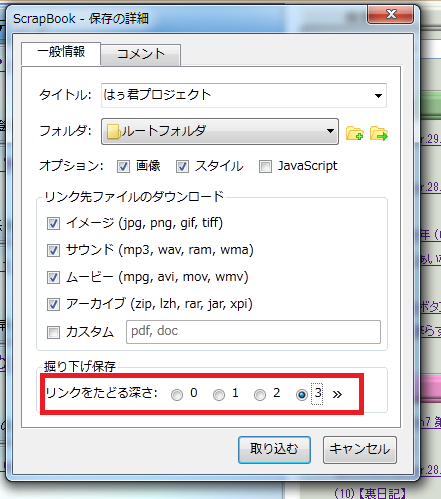
- 「リンク先ファイルのダウンロード」
画像や動画なども拡張子でフィルタリングして保存することができます。 - 「掘り下げ保存」
どのレベルまで深く見ていくかを設定することができます。3の横の>>で任意の数を指定することが可能です。
ScrapBookプラグインは、対象ページに貼ってあるリンクのうち、まだ未ダウンロードのページをダウンロードし、ダウンロードしたページに対して、同じことを繰り返して行きます。その深さの回数のようです。
ちなみに旧はぅ君プロジェクトのダウンロード時は深さ「10」を指定しました。
4.ダウンロード開始
取り込みが開始すると、ページ内のリンクを片っ端から調べてダウンロードしていきます。
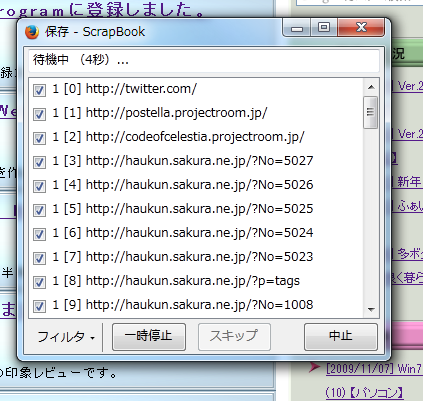
この時、フィルタメニューで、「ドメインで制御」しておくと、リンク先が同じドメインである場合のみダウンロード対象になります。
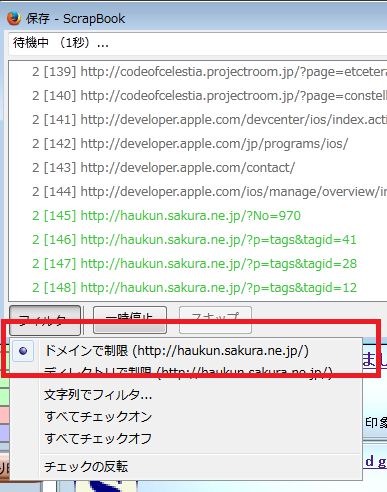 旧はぅ君プロジェクトは、Twitterや楽天アフィリエイト等の別サイトへのリンクがあり、そこは保存したくなかったので、「ドメインで制御」でダウンロードしました。
旧はぅ君プロジェクトは、Twitterや楽天アフィリエイト等の別サイトへのリンクがあり、そこは保存したくなかったので、「ドメインで制御」でダウンロードしました。
5.ダウンロードファイルの確認
ダウンロード後、リンク先が新しいものに書き変わります。
ダウンロードしたファイルは、私の場合は「C:\Users\[ユーザー名]\AppData\Roaming\Mozilla\Firefox\Profiles\wan8glun.default\ScrapBook\data」にありました。(環境はWindows7)
AppDataフォルダは隠しフォルダなので、表示するように設定してないと見えません。

コメント